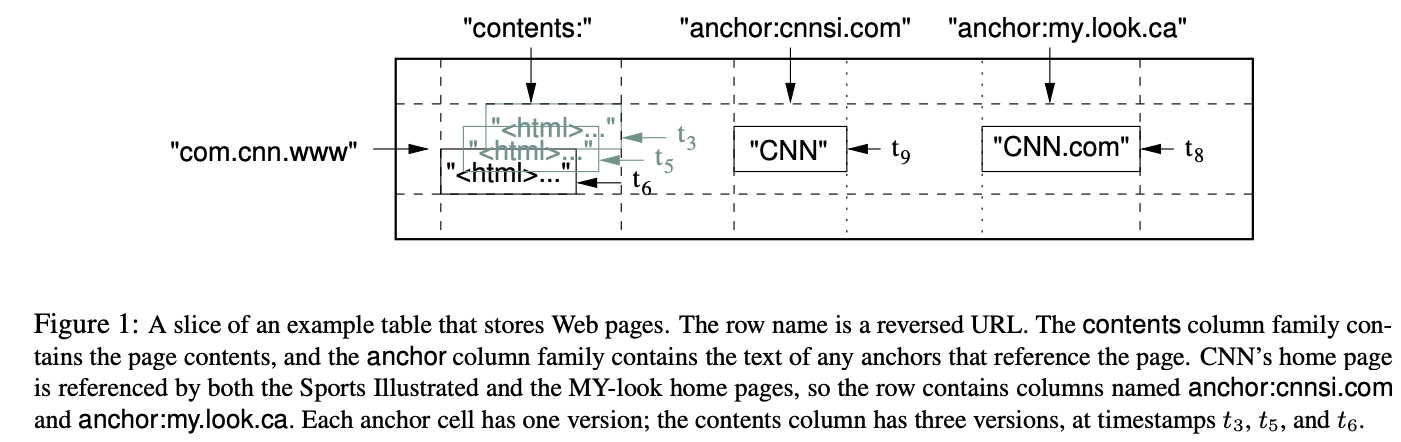
Bigtable 의 Building Block
Bigtable 은 다음과 같은 building block 으로 구성되어 있다.
- distributed GFS(Google File System)
- Cluster Management System
- SSTable
- Chubby
하나씩 살펴보자.
1. GFS
GFS 는 구글에서 만든 분산 파일 시스템이다. GFS 는 Bigtable 에서 로그 파일과 데이터 파일을 저장하기 위한 데이터 저장소로 사용된다. GFS 는 다음과 같은 특징을 가지고 있다.
High Scalability, Availability: 메타데이터를 관리하는 Master 서버, 실제 chunk 데이터가 저장되는 다수의 Chunk 서버의 역할 분리로, 분산된 파일 시스템을 구현Fault Tolerance: 각 청크 (chunk) 는 64MB 크기로 고정되어 있으며, 여러 청크 서버에 중복 저장High Throughput: 클라이언트가 직접 청크 서버와 상호작용 하는 방식으로, 마스터 서버 병목을 줄임. 또한 손쉽게 서버를 확장가능한 구조Optimization on Data structure: 큰 청크 단위 읽기로 Disk I/O 효율화, 블록 인덱스를 통한 빠른 검색, 메타데이터 캐싱
| ⁉️잠깐 CS 지식: 왜 큰 chunk 단위로 읽으면 Disk I/O 가 좋아지는가?
- 디스크는 물리적으로 데이터를 읽어오는 장치이므로, 디스크의 물리적 위치에 따라 읽기 속도가 달라진다.
- HDD, SDD 등 디스크에서 데이터에 접근할 때, 일정한 초기 오버헤드(seek time 등)가 발생한다.
- 따라서 작은 chunk 단위로 읽으면, 매번 디스크의 물리적 위치를 이동해야 하므로 오버헤드가 커지는 반면, 큰 Chunk 단위로 읽으면 줄어든다.
- 큰 chunk 단위로 읽어오면, 캐시 히트율이 높아져서, 디스크 I/O 가 줄어들게 된다.
- 큰 chunk 단위로 읽어오면, Sequential I/O 의 장점이 극대화 되는 반면, 작은 chunk 는 Random I/O 의 단점이 부각 된다. (Sequential I/O vs Random I/O)
2. Cluster Management System
- Bigtable cluster 는 여러 종류의 분산 어플리케이션이 실행되는 Shared Machine Pool 이다.
- 이 cluster management system 은 task scheduling, resource allocation, machine monitoring, fault detection, recovery 등을 기능을 수행한다.
3. SSTable
SSTable(Sorted String Table) 은 Bigtable 에서 데이터를 저장할 때 사용되는 자료 구조이다. 간단히 말하면 key/value string pair 인데, key 를 기준으로 정렬된 table 이라 할 수 있다. SSTable 은 다음과 같은 특징을 가지고 있다.
- key 는 중복을 허용하지 않으며 immutable 하다.
- 64KB 단위로 chunking 되어 block 으로 저장된다.
- 각 블록을 indexing 하는 Block index 가 각 SSTable에 저장되며, SST 가 open 될 때 메모리에 load된다.
기본 구조는 심플한데 정리하자면, SST 는 "key/value pair 형태의 구조이며, 64kb 단위로 chunk 가 만들어서져서 블록단위 indexing이 되겠구나" 라고 이해해볼 수 있겠다.
예시를 보자면, 다음과 같이 이름:값 쌍으로 이루어진 key/value pair 가 있고,
 출처:
출처: Amelia, Lily, Neil 로 시작되는 각 Block으로 chunking 된다고 했을 때, index 는 아래와 같이 저장된다.
 출처:
출처: 메모리에 load 된 block index 는 각 블록이 다루는 key 로 정렬되어있어 binary search 가 가능하다. 이를 통해 찾고자하는 key 가 어떤 block 에 포함되는지 알아내서 single disk seek 으로 해당 블록을 읽어올 수 있다. 한번 block 을 disk 에서 읽어와 메모리로 load 하면, 해당 key 를 찾는 것은 binary search 를 하거나 iterator 를 통해 순차적으로 비교하며 찾을 수 있을 것이다.
여기까지가 기본적인 SSTable 의 구조와 개념이지만, 다른 자료들을 보면 아래와 같이 Filter Block, Meta Index Block 등 으로 구성된 SSTable 을 설명하는 글도 찾아볼 수 있다.
 출처: SSTable
출처: SSTable
이는 google이 Bigtable 이후에 이를 베이스로 단일 노드 환경에 최적화 되도록 개량한 LevelDB 에서 기존 SST 의 최적화를 위해 개선한 구조로 보여진다.
Bloom filter 등 RocksDB 에서도 자주 보이는 keyword 들이 등장하는데, 추후 LevelDB 를 정리할 때 다시 정리해보겠다.
4. Chubby
Chubby 는 구글에서 만든 분산 환경에서의 동기화, Lock 관리, 메타데이터 저장 등의 작업을 수행하는 Distributed Lock Service 로 분산 코디네이션(coordination) 서비스중 하나이다. "어? 이거 Zookeeper 아니야?" 라고 생각할 수 있는데, 코디네이션의 역할은 같지만, 합의 알고리즘 등 세부적인 내용이 다르다. 또한, Chubby 는 apache 오픈소스인 Zookeeper 보다 먼저 만들어진 서비스이기 때문에 Zookeeper 가 Chubby 의 영향을 받아 만들어졌다고 볼 수 있다.
Chubby 의 구조를 구체적으로 설명하려면, Paxos 알고리즘을 합의 알고리즘을 사용하고 5개의 replica 중 하나가 master 로 선출되며, atomic Read/Write 방식 등.. 다룰 내용이 꽤 많다. 이는 Bigtable 과 마찬가지로 별도의 논문이 하나 있을 정도로 정리가 필요할 것 같아 추후 따로 정리를 하는 거로 하고, 여기서는 Chubby 가 Bigtable 에서 다음과 같은 목적으로 쓰인다는 것만 이해해두자.
- Bigtable 의 단일 활성 마스터 보장: Chubby 의 리더 선출 방식을 통해
- 메타데이터 및 스키마 저장: column family, ACL 등 메타데이터를 chubby 에 저정하여, client 에서 참조가능하도록 함
- Tablet 서버 탐지 및 관리: Tablet 서버의 등록, 상태 모니터링, 실패 후 종료 처리등 지원
- 부트스트랩(bootstrap) 정보 제공: Bigtable 데이터의 초기 boostrap 위치(데이터 파일의 위치 등)를 Chubby 에 저장, 복구 시에 Chubby 에서 빠르게 정보를 읽어와 복구 가능
자, 여기까지가 Bigtable 을 구성하는 핵심 Building Block 들에 대한 간략한 정리이다. 나는 이를 정리하면서 GFS, Chubby, SSTable 등 이미 구글에서 만든 기술들을 잘 활용하여, Bigtable 이라는 멋진 아키텍처를 만들었다는 점에서, 구글의 기술력에 감탄하지 않을 수 없었다. 사실상, 구글의 관점에서는 회사 자체의 기술력을 다 zero-base 로 시작한 것이 다름없다. (물론, Chubby 에서는 갓-포트 형님의 Paxos 알고리즘 등 third-party techinq 을 활용하긴 하지만..)
다음으론 Tablet 을 관리하는 방식, 데이터를 압축하는 방식 등에 대한 구현을 집중적으로 분석해보고, 논문을 낼 당시엔 적용이 안됬지만 Future works 로 남겨둔 것으로 보여지는 Refinements (high performance, availability, and reliability 를 얻기위해 refactoring 이 필요한 구조들) 가 어떤 것들이 있는지 정리해보겠다.
 출처:
출처: